- AI with Kyle
- Posts
- AI with Kyle Daily Update 175

Anthropic blinked. For about four hours yesterday they quietly pulled Claude Code out of the $20 Pro plan. George Pu spotted it, 2.3 million people saw his tweet, OpenAI's Codex team took a public swing, and Anthropic reverted the page worldwide.
That reversal is not a victory. At most it’s a reprieve. Most likely it’s a preview.
The flat-fee era of AI is ending, and your $20-a-month subscription is living on borrowed time. Sorry.
Anthropic Just Blinked
Here’s the time line.
George Pu spotted Claude Code removed from the $20 Pro plan. No announcement. No email. Just gone from the pricing page. Only available on the $100 and $200 plans. The tweet hit 2.3 million views overnight on the tweet.
Amol Avasare, Anthropic's Head of Growth, posted a reply: "For clarity, we are running a small test on ~2% of new prosumer signups. Existing Pro and Max subscribers are not affected."
They were probably hoping 2M+ people didn’t see their “test”. OOPS.
Tibo Sottiaux from OpenAI's Codex team swept in and took the shot: "I don't know what they're doing over there. Codex will continue to be available on the free and plus plans. Transparency and trust are two principles we will not break even if it means momentarily earning less."
The next day Anthropic reverted the pricing page worldwide. The 2% test had leaked to everyone. Very publicaly.
Drama!
Kyle's take: The test itself kinda doesn't matter. What matters is that Anthropic ran it at all. They looked at their unit economics on $20 Pro users burning hour-long Claude Code sessions and decided it wasn't sustainable. More on this below.
They tried to do something about it. They got caught. They backed off. But the maths that made them try has not changed. They will 100% be pulling Code from $20 plans this year - I’m willing to bet on that one.
Codex meanwhile has been absolutely on fire the last month while Claude has been messy. I wouldn't be surprised if we're about to see a public sentiment swing back to ChatGPT.
What It Means For Your Plan
Right now: nothing. It’s business as usual. BUT Anthropic will likely try to push this later when the dust settles.
If you're on $20 Pro right now, you're safe. Your plan still includes Claude Code. The access is relatively limited on that tier but it's there. I've got a private WhatsApp group where people who started on $20 a month quickly upgrade to $100 once they see how powerful it is.
If you signed up in the last day or two and something looks off, go check your plan. The 2% test caught some accounts mid-flight. The page was reverted but it's worth a look just to see if you got caught in the test. Unlikely but make sure to check!
If you rely on Claude Code for real work, you're probably already on $100 or $200 a month. Plan for that to stay your floor. Like Pro will go to $100 and Max will be $200. Everything shifted one to the right.
The $20 on-ramp is on borrowed time. Honestly, $100 a month for Claude Code is the best subscription I spend money on. I'm struggling to think of a better one…
Kyle's take: If you're running a business on Claude Code right now, use the next six months to hedge. Test Codex in parallel this week. Set up Ollama on a spare machine. The people who get burned will be those who bet their entire pipeline on one subscription and never hedged. There are PLENTY of warning signs right now.
"Intelligence Too Cheap To Meter" Was A Story
Sam Altman said this around the release of 4o-mini, a couple of years ago. He said it at a Fed speech. He repeated it at the BlackRock Infrastructure Summit in March. Every AI keynote recycled the line for a while.
Here's what's true: per-token prices have collapsed. Roughly 280x drop in AI token costs over two years. That is a massive drop. Intelligence on a per-token basis genuinely got cheaper.
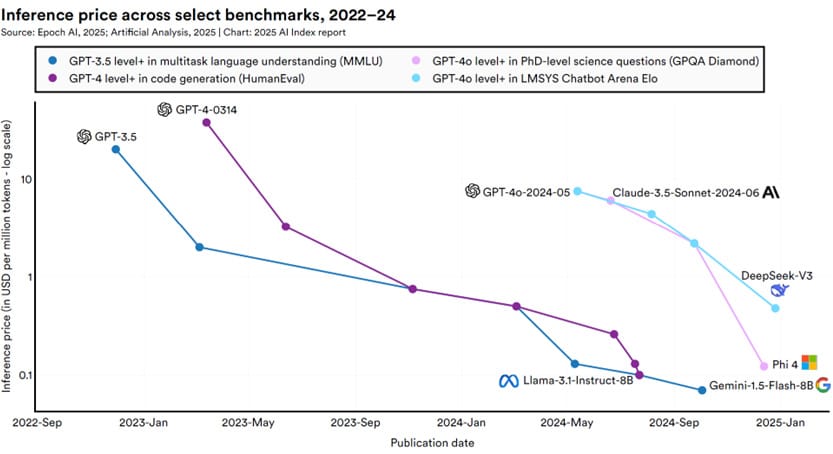
Here's what's not: your per-user bill is going up. Anthropic just tried to push Pro users from $20 to $100. That's a 5x jump. The reason is simple: two years ago we were chatting to AI. Back and forth, a few hundred tokens per session. Now we're running Claude Code, Codex, Claude Design, agents that chat to themselves for 20, 30, 40 minutes at a stretch, burning through tokens in a much greedier way than a human ever could. I've got three agents running in the background right now while doing this stream.

This is Jevon’s Paradox. When something gets cheaper, people use dramatically more of it. Cheaper electricity meant more electricity consumption, not less. Cheaper tokens means more tokens burned, not less. Despite the efficiencies MORE is used. Both things are true at the same time.

The "too cheap to meter" line was marketing, not maths. It was always going to be marketing. Your 2026 reality is that per-user bills are going up because you're using these tools 1000x more than you were two years ago.
Altman recently (March 2026) adjusted the narrative to this too - AI as a utility with “pay as you go” pricing.
Two Costs. Only One Is Falling.
Every AI company has two cost lines and you need to understand both.

Training is the cost to build the model. Think setting up the kitchen, hiring the staff, building the restaurant. You pay it once per model, then amortise across every future query. Frontier models now cost $100 million plus. Next-gen is estimated in the billions. Direction is up as models scale. But they are one time costs.
Inference is the cost to run the model. Think ordering from the menu - food going back and forth every single time. Inference scales with usage. As more people use AI more intensively, the inference bill balloons. It's now 80 to 90 percent of all AI compute load as of 2026. Agents running for hours multiply this by 1000x per user.
In the recent fracas Amol Avasare actually said the quiet part out loud: "Our current plans weren't built for this." He is straight up saying that this is unsustainable. This feels like CEO level communication rather than something to drop in a random tweet but hey at least we got the truth!
Basically nobody priced a $20 subscription assuming one user would run an agent for eight hours a day. That's what's happening now.
This is why flat-fee pricing will die. It's not corporate greed. That’s too simplistic. Instead it's maths. When your top users consume 100x more inference than your median user, a single subscription price stops working. Light users subsidise heavy users until the company notices, runs the numbers, and starts testing what a realistic price looks like. That's exactly what Anthropic just did - and got caught doing! BUT expect every major AI tool to add usage caps or tiered metered billing within six months.
Anthropic and OpenAI originally priced AI like Netflix. $20 a month, all-you-can-eat, feels about right. That was a marketing decision, not a pricing one. And they probably just plucked $20/month from the air because that felt right. Now the industry is maturing and realising light users can't subsidise heavy users forever.
So the pitch is changing. They're reframing AI from "SaaS subscription" to "employee cost". Claude Design isn't $1000 a month compared to Photoshop at $20. Claude Design is $1000 a month compared to a $5000-a-month designer. Totally different pricing anchors and market. Suddenly the price looks reasonable. THAT’s the transition these companies are trying to make.
So What Do You Actually Do?
OK that’s all well and go. We understand WHY. But what do we actually DO?

Right now: try ChatGPT Codex. It's good. Genuinely competitive with Claude Code. The Codex team has been absolutely on fire for the last month while Claude has been messy. OpenAI just publicly committed to Free and $20 tiers with advance notice of changes. They have the compute. The limits are generous - and they keep capitalising on Anthropic’s missteps by resetting Codex limits…
It's become a meme. There's literally an image of him resetting the limits…
6 to 12 months: go local. Go open source. Qwen Coder, GLM, MiniMax and Kimi are closing the coding gap. Run them via Ollama or LM Studio. LM Studio is free, dead simple - click, pick a model, it downloads and runs. It’s not technical - it’s all plug and play nowadays.
Always: make do with less. Token hygiene wins. Default to smaller models like Haiku or GPT-5 mini for routine work. You don't need Opus 4.7 for a tweet draft. Turn on prompt caching so your system prompt isn't re-billed every turn. Feed the model the specific file, not the entire repo. Just because you have a 1 million token context window does not mean you should fill it. Write specific prompts - for examples 4.7 needs a better prompt than 4.6. Build a library of saved Skills.
Kyle